En este post iré añadiendo las expresiones regulares que uso en mis desarrollos. De este modo, puede ser útil para alguien e incluso para mi, para poder venir a este artículo si no recuerdo alguno. Son muy útiles para scraping, análisis de datos…
Tabla de Contenidos
Obtener Atributos de HTML
Con este REGEX se encuentran los atributos de documentos en HTML que te interesen borrar o modificar, independientemente de su contenido. Por ejemplo, eliminar todas las «id» del contenido HTML, eliminar todos los estilos (atributo style), cambiar todos los enlaces «href»…

Todas las clases del HTML: class="[^\"]*" Todas las id del HTML: id="[^\"]*" Todas los href del HTML: href="[^\"]*" Todos los style del HTML: id="[^\"]*" (Y así con todos los atributos HTML)
Ejemplo
Extraer Contenido Entre Dos Palabras / Etiquetas
Con este REGEX se extrae el contenido entre dos cadenas de texto. Yo lo suelo usar mucho para eliminar etiquetas HTML que no me interesan de un scraping. Por ejemplo, para quitar todas las etiquetas <script> de un HTML.

Todas los script del HTML: <script(.*?)<\/script> Todos los encabezados h1 del HTML: <h1(.*?)<\/h1> Todos los enlaces del HTML: <a(.*?)<\/a> Todos los comentarios del HTML: <!--(.*?)--> (Y así con todas las etiquetas HTML)
Ejemplo
Añadir Prefijo o Sufijo a Líneas
Este REGEX es muy útil para modificar datos scrapeados. Hace lo mismo que la herramienta Add Prefix and/or Suffix into Each Line de Cerveza.gratis, pero si prefieres hacer las modificaciones en tu editor de texto puede ser muy útil. Simplemente añade un texto al principio de todas las líneas y al final, cada uno con un código diferente. Es uno de las expresiones regulares más simples, pero a la vez de las más útiles.
En este ejemplo, partiendo de los ASIN-es scrapeados de Amazon, creo su URL:

Añadir prefijo: ^ Añadir sufijo: $
Ejemplo
Extraer Primer y Último Carácter de Múltiples Líneas
Por otro lado, para editar el primer o último carácter de un fichero con miles de líneas de forma masiva, está este simple código de REGEX. Es muy útil para editar datos scrapeados. Por ejemplo, imaginémonos que de los ASIN-es anteriormente scrapeados, nos ha quedado un asterisco al inicio y una barra al final. Los quitaríamos así:

Borrar primer carácter:
Buscar: ^.(.*)$ Reemplazar: $1
Borrar último carácter
Buscar: .$ Reemplazar:
Ejemplo
Extraer Todo Después de Una Palabra
Con esta expresión regular se puede extraer todo el contenido después un carácter o una palabra. Como se muestra en la siguiente imágen, se puede utilizar para limpiar URL-s por ejemplo.
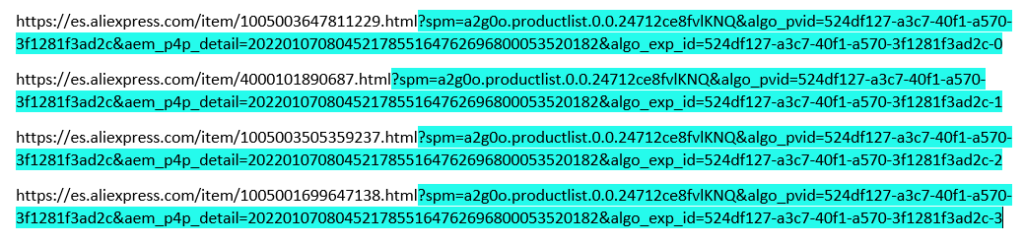
Incluir Palabra: (?=PALABRA).*$ Sin incluir Palabra: (?<=PALABRA).*$
Ejemplo
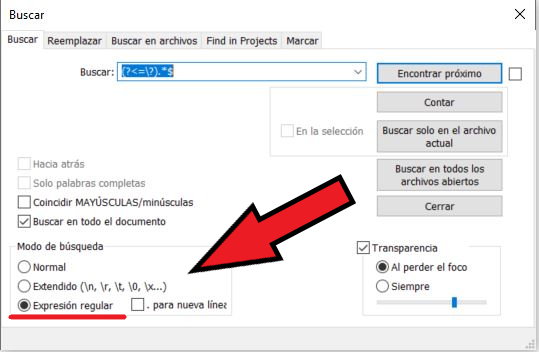
¿Cómo Usar REGEX o Expersiones Regulares?
Pues depende un poco de donde o cómo los quieras usar, pero lo más sencillo es usarlo en un editor de texto. Cada editor tiene su forma de hacerlo, pero por ejemplo, en Notepad++, uno de los editores más usados, es simplemente darle a «Buscar» o «Control + F», y seleccionar la opción de «Regular Expression». Luego solo sería ir a «Reemplazar» y ir cambiando o eliminando lo que te interese. No obstante, las expresiones regulares también se pueden usar el multitud de otras formas.