Buenas a todos! En este post os presento un pequeño script que he desarrollado en Python para poder extraer los correos electrónicos de las páginas web, de una forma masiva, cómoda y sobre todo rápida.
Tabla de Contenidos
Funcionamiento del Script

El funcionamiento del script es muy sencillo como podéis ver en el código fuente en Github. Lo que hace es ir abriendo las webs especificadas uno a uno y busca en la página si existe algún email escrito. Esto lo repite 4 veces hasta encontrar el email. Es decir, primero abre la url raíz, por ejemplo «https://juaristech.com/», y si no lo encuentra, pasa a buscar en «https://juaristech.com/contacto» y si tampoco lo encuentra, lo prueba con «https://juaristech.com/contactar» y esto lo repite con «contactame» y «aviso-legal» también. Lo más normal es que lo encuentre en la página raíz o sino en la de «-contacto», pero las otras están por si acaso.
Si encuentra el email, lo va almacenando en una lista, y cuando acaba el proceso exporta esa información a un fichero Excel, llamado «emails_output.xls».
El proceso para ejecutar el script es realmente sencillo, consta de dos pasos, extraer la lista de URL-s y almacenarlos en el fichero específico, y después ejecutar el script en la línea de comandos especificando el idioma de las webs. Te explico los dos pasos a continuación:
Extraer la lista de URL-s de las webs
Lo primero que vas a necesitar es tener la lista de las URL de las webs donde quieres extraer los correos electrónicos. Hay miles de formas, y lo más probable es que obtengas esta lista habiendo hecho algún tipo de scrapeo. No obstante, un método que yo uso algunas veces para extraer las urls de las webs que están en las primeras posiciones para alguna keyword concreta, es la de ir abriendo todas las webs de los primeros 20 resultados, y luego con la extensión de Copy All Urls, copiar las url, y pasarlas al fichero de texto.
En este ejemplo, hice la técnica mencionada con las autoescuelas, buscando la palabra «autoescuela» en el buscador, abriendo algunos de los primeros resultados y copiando las url. Cuando tengas las URL, las tienes que pegar en el fichero «webpages.txt».
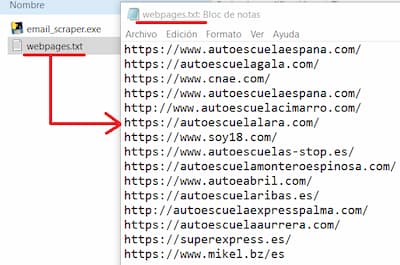
Ejecutar el script
Una vez que ya hayas introducido las URL de las webs en el fichero «webpages.txt», solo tienes que ejecutar el script especificando en que idiomas están las webs. En este momento, el script funciona para webs en español y en inglés.
El proceso es muy sencillo. Descarga el fichero .rar, extrae la carpeta, y entra en ella. En caso de que hayas descargado el repositorio de Github, entra en la carpeta «build». Ahí abre una linea de comandos. Lo puedes hacer fácilmente de esta forma:
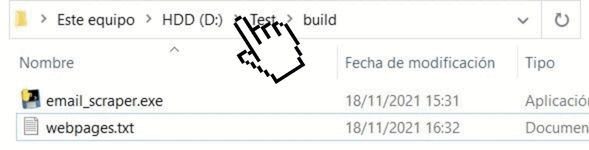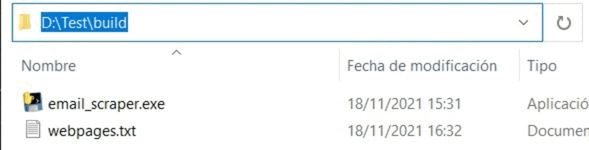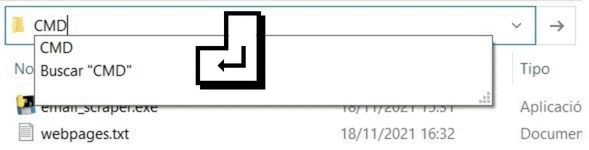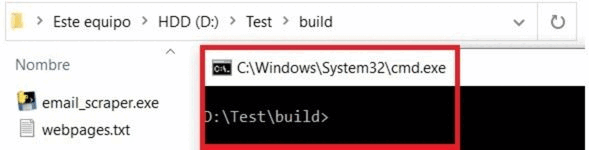
Una vez que tengas abierta la línea de comandos, solo te queda ejecutar el script. Tienes que escribir lo siguiente:
Para webs en inglés:
> email_scraper.exe ENPara webs en castellano:
> email_scraper.exe ESCon esto ya empezaría el script a ejecutarse y al acabar, en esa misma carpeta se creara un fichero emails_output.xls con los resultados del scraping.

Video explicativo
También he creado un pequeño vídeo para que veas como se ejecuta y funciona el script.
2ª Versión: Scrapear con URL-s específicas
Además, he añadido otra versión del script abajo, para casos en los que interese directamente scrapear los email de URL-s específicas, sin tener que ir buscando la página de contacto, o sobre nosotros en busca del email.
Con este script, lo único que hay que hacer es añadir las URL y ejecutarlo. Al finalizar creará el mismo fichero Excel que con la otra versión.
Posibles Fallos
El código puede tener tres principales fallos o problemas:
- El script, almacena únicamente el primer correo electrónico que encuentra en la página. Por ello, en el caso en el que en la página haya más de un correo electrónico, puede darse el caso de que el correo obtenido no sea el de contacto.
- El scrapeo lo he hecho con Beautiful Soup, que es una librería para analizar HTML y scrapear. Pero hay páginas que su HTML lo cargan mediante Javascript, y al tener que renderizarse, Beautiful Soup no lo puede leer. Esto haciéndolo con Selenium si que sería posible, pero por ahora no lo he implementado. No obstante, las páginas que cargan su HTML renderizándolo con Javascript son la gran minoría.
- Por último, y como habréis podido observar, en el Excel no aparecen todas las columnas de la derecha rellenas. El no poder obtener el email, se puede deber a que en la página principal, en la de «-contacto», «-contactar» y las páginas especificadas en el script, no haya ningún correo electrónico, o por algún error externo.
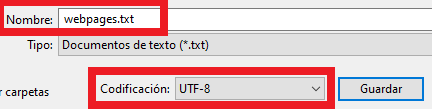
- Codificación del fichero de texto: El fichero de texto llamado «webpages.txt» que se encuentra en el mismo directorio que el script, tiene que estar codificado en UTF-8. Windows por defecto guarda los ficheros de texto en UTF-16. Se puede elegir al guardar el fichero de texto.
Enlaces de Descarga
Aquí te dejo los enlaces de descarga, tanto si quieres primero revisar el código y descargarlo desde GitHub, como si solo te interesa descargar el fichero ejecutable:
Hola Juaris, excelente script
Quería probarlo pero al ejecutar aparece este mensaje en windows
«Acceso denegado. No se puede ejecutar la aplicación en el equipo»
¿Alguna idea?
Buenas! Puede que el antivirus o el firewall te este bloqueando el programa. Prueba a desactivarlo mientras uses el script y a ver si así funciona. Un saludo!
Egun on patxi , lo llevo intentando por activa y pasiva, pero tengo un mac y no lo consigo, algun tip? eskerrik asko
Hola Juaris pues está estupendo. Me surge un tema. En mi caso por ejemplo estoy buscando scrapear páginas en otro idioma (frances), donde lo típico es que la página de contacto se llame de otra manera.
Ya he visto que con la segunda versión se puede especificar una a una, pero claro, esto pierde funcionalidad. Sería posible acceder al código del exe para poder indicarle que variables de url debiera buscar en vez de contacto, contactar, etc ?
Muchas gracias, y felicitaciones por el script.
Hola Patxi! Han pasado dos años desde que publicaste este artículo, pero me vino de perlas ahora. Lo acabo de probar y me funciona correctamente. Muchas gracias y un saludo desde Galicia!